News
Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents Need
3+ hour, 45+ min ago (1496+ words) Making Developers Awesome at Machine Learning In this article, you will learn why short-term context isn't enough for autonomous agents and how to design long-term memory that keeps them reliable across extended timelines. Topics we will cover include: Let's get…...
Train Your Large Model on Multiple GPUs with Pipeline Parallelism
17+ hour, 49+ min ago (1329+ words) Making Developers Awesome at Machine Learning This article is divided into six parts; they are: Pipeline parallelism means creating the model as a pipeline of stages. If you have worked on a scikit-learn project, you may be familiar with the…...
5 Python Libraries for Advanced Time Series Forecasting
1+ day, 3+ hour ago (364+ words) Making Developers Awesome at Machine Learning Fortunately, Python's ecosystem has evolved to meet this demand. The landscape has shifted from purely statistical packages to a rich array of libraries that integrate deep learning, machine learning pipelines, and classical econometrics. But…...
Training a Model on Multiple GPUs with Data Parallelism
4+ day, 8+ hour ago (976+ words) Making Developers Awesome at Machine Learning Training a large language model is slow. If you have multiple GPUs, you can accelerate training by distributing the workload across them to run in parallel. In this article, you will learn about data…...
Train a Model Faster with torch.compile and Gradient Accumulation
4+ day, 22+ hour ago (534+ words) Making Developers Awesome at Machine Learning Training a language model with a deep transformer architecture is time-consuming. However, there are techniques you can use to accelerate training. In this article, you will learn about: This article is divided into two…...
Training a Model with Limited Memory using Mixed Precision and Gradient Checkpointing
5+ day, 21+ hour ago (749+ words) Making Developers Awesome at Machine Learning Training a language model is memory-intensive, not only because the model itself is large but also because the long sequences in the training data batches. Training a model with limited memory is challenging. In…...
Evaluating Perplexity on Language Models
 6+ day, 22+ hour ago (401+ words) Making Developers Awesome at Machine Learning A language model is a probability distribution over sequences of tokens. When you train a language model, you want to measure how accurately it predicts human language use. This is a difficult task, and…...
6+ day, 22+ hour ago (401+ words) Making Developers Awesome at Machine Learning A language model is a probability distribution over sequences of tokens. When you train a language model, you want to measure how accurately it predicts human language use. This is a difficult task, and…...
3 Smart Ways to Encode Categorical Features for Machine Learning
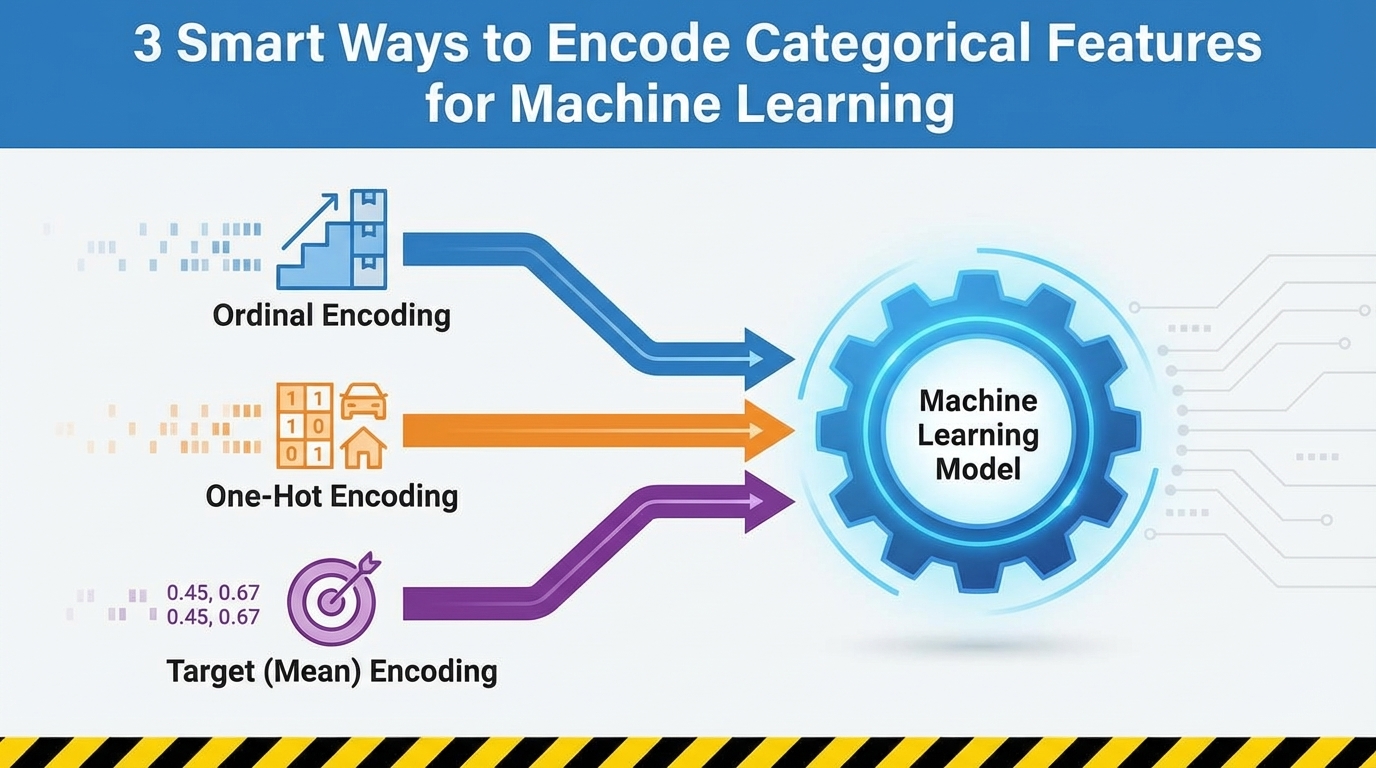 1+ week, 22+ hour ago (1190+ words) Making Developers Awesome at Machine Learning In this article, you will learn three reliable techniques " ordinal encoding, one-hot encoding, and target (mean) encoding " for turning categorical features into model-ready numbers while preserving their meaning. Topics we will cover include: Time…...
1+ week, 22+ hour ago (1190+ words) Making Developers Awesome at Machine Learning In this article, you will learn three reliable techniques " ordinal encoding, one-hot encoding, and target (mean) encoding " for turning categorical features into model-ready numbers while preserving their meaning. Topics we will cover include: Time…...
Pretraining a Llama Model on Your Local GPU
 1+ week, 1+ day ago (913+ words) Making Developers Awesome at Machine Learning Decoder-only language models like Llama are usually trained using self-supervised learning objectives on large amounts of text. This is called pretraining to distinguish it from later fine-tuning steps on specific tasks. In this article,…...
1+ week, 1+ day ago (913+ words) Making Developers Awesome at Machine Learning Decoder-only language models like Llama are usually trained using self-supervised learning objectives on large amounts of text. This is called pretraining to distinguish it from later fine-tuning steps on specific tasks. In this article,…...
Rotary Position Embeddings for Long Context Length
 1+ week, 1+ day ago (624+ words) Making Developers Awesome at Machine Learning Rotary Position Embeddings (RoPE) is a technique for encoding token positions in a sequence. It is widely used in many models and works well for standard context lengths. However, it requires adaptation for longer…...
1+ week, 1+ day ago (624+ words) Making Developers Awesome at Machine Learning Rotary Position Embeddings (RoPE) is a technique for encoding token positions in a sequence. It is widely used in many models and works well for standard context lengths. However, it requires adaptation for longer…...